|
|
|
Архив статей Обновление: 30.05.2014 Всего статей: 18 Ремонт и сервис Обновление: 01.05.2014 Документов: 8 Программирование Обновление: 18.04.2014 Разделов: 2 Скачать Общий объём: 4.3 Mb Файлов: 12 |
|
ICQ: 680172615 rumit-71@mail.ru |
|
Наши новости
24.05.2014 Полность переработано содержимое и обновлён интерфейс сайта 01.05.2014 Добавлены статьи в разделы "Ремонт и сервис", "Железо" 01.05.2014 Добавлены несколько нужных программы для бесплатного пользования |
|
Подсистема памяти
Основные понятия. Работа процессора с памятью.Невозможно понять работу памяти, не уделив внимание работе центрального процессора, т.к. именно память является рабочей областью ЦП. Рассмотрим некоторые характеристики ЦП, в том числе разрядность шины данных и адреса и быстродействие.Быстродействие - довольно простой параметр. Оно измеряется в Гигагерцах: 1GHz равен миллиарду тактов в секунду. Чем выше быстродействие - тем быстрее процессор! Разрядность - параметр более сложный. В ЦП входит 2 важных устройства, основной характеристикой которых является разрядность:
- шина ввода/вывода данных Разрядность шины ввода/вывода данных подобна количеству полос движения на скоростной автомагистрали; точно также, как увеличение кол-ва полос позволяет увеличить поток машин на трассе, увеличение разрядности позволяет повысить производительность. Чем больше линий, тем больше битов можно передать за момент времени.
Современные процессоры типа Pentium имеют 64-разрядные шины данных. Это означает, что эти ЦП могут передавать в системную память (или получать из неё) одновременно 64 бит (8 байт) данных.
Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F
00001000 41 00 4C 00 4C 00 55 00 53 00 45 00 52 00 53 00
00001010 50 00 52 00 4F 00 46 00 49 00 4C 00 45 00 3D 00
00001020 43 00 3A 00 5C 00 44 00 6F 00 63 00 75 00 6D 00
00001030 65 00 6E 00 74 00 73 00 20 00 61 00 6E 00 64 00
.к. ОЗУ и ЦП работают на разных частотах, то процессор не может считать этот пакет данных за один такт. Ему приходится подстраиваться под частоту памяти и простаивать несколько тактов в ожидании. Сколько раз ЦП стукнет в холостую, зависит от установленных таймингов памяти! К примеру, мои тайминги имеют такие значения: 3-3-3-9. Суммируя эти значение мы получаем длительность одного цикла обращения к памяти - 18 тактов ЦП. От сюда следует, что для чтения 1-ой строки 16-разрядной памяти, процессор (с шириной шины данных 64-бит) должен простучать 36 тактов. Зная тактовую частоту ЦП (3.0 GHz) и длительность цикла (18 тактов), путём несложных вычислений можно расчитать время одного цикла обращения к памяти (~6 ns):
3 000 000 000 тактов = 1 секунда 18 тактов = ? секунд ------------------------ 18 / 3 000 000 000 = 0,000000006 сек.Шина адреса представляет собой набор проводников; по ним передаётся адрес ячейки памяти, в которую (или из которой) пересылаются данные. Как и в шине данных, по каждому проводнику передаётся 1 бит адреса. Увеличение количества проводников/разрядов используемых для формирования адреса, позволяет увеличить кол-во адресуемых ячеек памяти. Разрядность шины адреса определяет макс.объём памяти, адресуемой ЦП. В компьютерах применяется бинарная система счисления, поэтому при 2-разрядной адресации можно выбрать только 4 ячейки (с адресами 00,01,10,11), при 3-разрядной - 8 ячеек (от 000 до 111) и т.д. В современных процессорах ширина шины адреса составляет 32-36 бит, что позволяет адресовать 4-64 гигабайт памяти соответственно. Шины адреса и данных независимы и разработчики выбирают их разрядность по своему усмотрению - чем больше разрядов в шине данных, тем больше их и в шине адреса. Кол-во разрядов в шине данных определяет способность ЦП обмениваться информацией, а разрядность шины адреса - объём памяти, с которым он может оперировать. Процессор работает с оперативной памятью, так как в ней хранятся данные, необходимые процессору для работы. В оперативную память процессор помещает результаты своих вычислений, перед окончательным сохранением в долговременной памяти. Взаимодействие процессора с памятью происходит посредством шин адреса, данных и управления.
Ячейка оперативной памяти. Принцип действияРассмотрим структурную схему ячейки динамической оперативной памяти (DRAM). Её можно представить из трёх элементов:
– транзистора, выполняющего роль ключа;
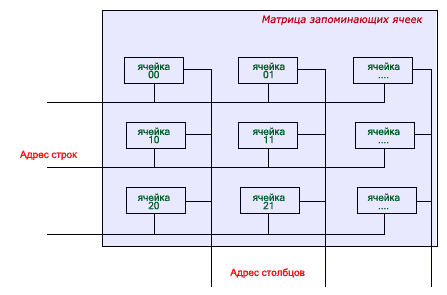
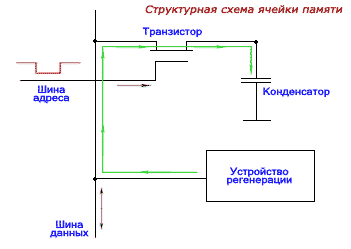 На самом деле, отдельного конденсатора нет, его роль выполняет ёмкость между затвором и истоком транзистора. Но для простоты изложения ёмкость выделена как бы в отдельный элемент. Поскольку ёмкость достаточно маленькая и имеет место быстрый её разряд, возникает необходимость в регенерации (подзарядки конденсатора). Кроме того, при считывании информации из ячейки оперативной памяти, заряд также исчезает, поэтому и в этом случае необходима регенерация. Эту часть работы берёт на себя "Устройство регенерации". Процесс записи информации в ячейку оперативной памяти можно представит так. Если в ячейку необходимо записать «0» или же его регенерировать, то попросту к ячейке нет обращения, ...считается, что она и так «нулевая». В случае записи «1», на адресной шине появляется потенциал и в этот момент течёт ток от схемы регенерации, заряжая ёмкость. При считывании информации, также происходит разряд конденсатора, поэтому после считывания информации из ячейки динамической памяти, её необходимо восстановить. Процесс считывания происходит почти также, как и процесс записи. На адресную шину поступает сигнал, он преобразовывается в потенциал на адресном входе необходимой ячейки памяти, и по шине данных происходит считывание потенциала/информации, записанного в конденсаторе. Работу ячейки памяти можно представить таким образом. Конденсатор можно представить в виде ёмкости, в которую наливается вода. Транзистор в виде ключа или крана, который открывает или перекрывает трубу, по которой течёт вода в ёмкость, а устройство регенерации в виде источника воды. В нужный момент кран открывается и это служит признаком того, что необходимо пополнить ёмкость водой. Рассматривая работу ячейки памяти таким образом, можно представить, что ёмкость с водой немного дырявая. Это утверждение имеет под собой основание, т.к. конденсатор (в случае хранения «1» и до тех пор, пока она записана) должен постоянно подзаряжаться схемой регенерации. Ячейка памяти хранит в себе один бит информации. Для того чтобы динамическая память (DRAM) хранила-бы в себе мегабайты (а сейчас уже и гигабайты) данных, необходимо чтобы все эти элементарные ячейки памяти объединялись между собой в большие массивы или матрицы памяти. Мы уже знаем, что пара цифр в дампе имеет ёмкость 1 байт, а это 8 ячеек памяти! Технологически, одна строка 16-разрядной памяти состоит из (16*8) 128 элементарных ячеек:
Типы запоминающих устройствROM. Постоянные запоминающие устройстваПостоянные запоминающие устройства (ПЗУ или Read Only Memory - ROM) обеспечивают сохранение записанной в них информации и при отсутствии напряжения питания. Конечно, под такое определение попадают и жёсткие диски, и компакт диски, и некоторые другие виды ЗУ. Однако, говоря о постоянных ЗУ, обычно подразумевают устройства памяти с произвольным адресным доступом. Такие ЗУ могут строиться на различных физических принципах и обладать различными характеристиками (ёмкость, время обращения и т.д.) Различают две группы ПЗУ: программируемые изготовителем и программируемые пользователем. ЗУ первой группы, называемые иначе масочными, обычно выпускаются большими партиями. Информация в них заносится в процессе изготовления на заводах. В ПЗУ, программируемые пользователем, информация записывается после их изготовления самими пользователями. При этом существуют два основных типа таких ЗУ: однократно программируемые и пере/программируемые. Аналогичные разновидности имеются и у CD-ROM, которые по существу, являются ПЗУ (ROM). Наиболее простые - однократно программируемые ПЗУ. В них запись производится посредством разрушения соединительных перемычек между выводами транзисторов и шинами матрицы. Перепрограммируемые ПЗУ позволяют производить в них запись информации многократно. Конечно, в таких ЗУ должен использоваться иной принцип, чем разрушение перемычек в процессе записи. Распространенные технологические варианты используют МОП-транзисторы со сложным затвором (составным или плавающим), который способен накапливать заряд, снижающий пороговое напряжение отпирания транзистора, и сохранять этот заряд при выключенном питании. Программирование таких ПЗУ и состоит в создании зарядов на затворах тех транзисторов, где должны быть записаны данные (обычно “0”, так как в исходном состоянии в таких микросхемах записаны все “1”). Перед повторной записью требуется произвести стирание ранее записанной информации. Оно производится либо электрически, подачей напряжения обратной полярности, либо с помощью ультрафиолетового света. У микросхем последнего типа имелось круглое окошечко из кварцевого стекла, через которое и освещался кристалл при стирании. Ещё одним типом ПЗУ является флэш-память. Эта память - представитель класса перепрограммируемых постоянных ЗУ с электрическим стиранием. Однако стирание в ней осуществляется сразу целой области ячеек: блока или всей микросхемы. Это обеспечивает более быструю запись информации или, как иначе называют данную процедуру - прошивки. Флэш-память строится на однотранзисторных элементах памяти (с “плавающим” затвором), что обеспечивает плотность хранения данных выше, чем в динамической оперативной памяти (DRAM). Наиболее широко известны NOR и NAND типы флэш-памяти, запоминающие транзисторы в которых подключены к разрядным шинам, соответственно, параллельно и последовательно. Первый тип (NOR) имеет относительно большие размеры ячеек и быстрый произвольный доступ. Второй тип (NAND) имеет меньшие размеры ячеек и быстрый последовательный доступ, что более пригодно для построения устройств блочного типа, например твердотельных дисков. Элементы памяти флэш-ЗУ организованы в матрицы, как и в других видах полупроводниковой памяти. Разрядность шины данных составляет 8-16 бит. Разбиение адресного пространства микросхем флэш-памяти, обычно бывает двух видов: симметричное и асимметричное. При симметричном разбиении все блоки имеют одинаковый размер (64-128 Кбайт). Количество блоков зависит от ёмкости микросхемы. В случае асимметричной архитектуры (называемой иначе Boot Block) один из блоков, на которые разбито адресное пространство, дополнительно разбивается на меньшие блоки, один из которых может быть использован в качестве бут-блока. Флэш-память используется для различных целей. В РС эту память применяют для хранения BIOS, что позволяет при необходимости производить обновление последней, прямо на рабочей машине. Асинхронная динамическая память DRAM В качестве оперативных ЗУ в настоящее время используются динамические ЗУ с произвольным доступом (DRAM). Широкое распространение ЗУ этого типа проявилось в разработке многих его разновидностей: асинхронной, синхронной, RAMBUS и других. Основные из них рассматриваются далее. В процессе совершенствования технологий, изменялась и логика функционирования динамических ОЗУ. Первые такие ЗУ, которые впоследствии стали называть асинхронными, выполняли операции чтения/записи, получив лишь запускающий сигнал адреса RAS#. Диаграмма простых (не пакетных) циклов чтения/записи таких ЗУ представлена на рисунке:
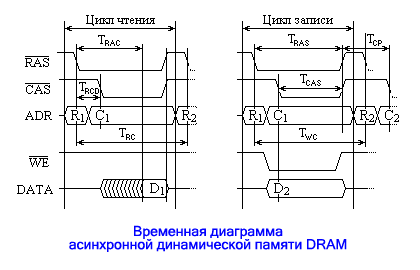 Любой цикл (чтения или записи) начинается по спаду (фронту “1”->“0”) сигнала RAS#. Как видно из диаграмм, адрес на шину адреса поступает двумя частями - адрес строки (обозначенный как R1 или R2) и адрес столбца (C1 и C2). В момент, когда на адресной шине установилось требуемое значение части адреса, соответствующий сигнал строба (RAS# или CAS#) переводится в активное (нулевое) состояние. В цикле чтения (сигнал WE# во время этого цикла удерживается в единичном состоянии) после подачи адреса строки и перевода сигнала CAS# в нулевое состояние, начинается извлечение данных из адресованных элементов памяти, что показано на диаграмме сигнала DATA как заштрихованная часть. По истечении времени доступа TRAC (RAS Access Time – задержка появления данных на выходе DATA, по отношению к моменту спада сигнала RAS#) на шине данных устанавливаются считанные из памяти данные. Теперь, после удержания данных на шине в течение времени, достаточного для их фиксации, сигналы RAS# и CAS# переводятся в единичное состояние, что указывает на окончание цикла обращения к памяти. Цикл записи начинается так же, как и цикл чтения, по спаду сигнала RAS#, после подачи адреса строки. Записываемые данные выставляются на шину данных одновременно с подачей адреса столбца, а сигнал разрешения записи WE# при этом переводится в нулевое состояние. По истечении времени, достаточного для записи данных в элементы памяти, сигналы данных WE#, RAS# и CAS# снимаются, что говорит об окончании цикла записи. Помимо названного параметра TRAC (времени доступа по отношению к сигналу RAS#), на диаграмме указаны ещё несколько времён:
- TRCD – минимальное время задержки между подачей сигналов RAS# и CAS# (RAS-to-CAS Delay); Подача адреса двумя частями удлиняет цикл обращения к памяти. Поскольку адрес строки является старшей частью адреса, то для последовательных адресов памяти, адрес строки одинаков. Это позволяет в (пакетном) цикле обращений по таким адресам задать адрес строки только для обращения по первому адресу, а для всех последующих задавать только адрес столбца. Такой способ получил название FPM (Fast Page Mode – быстрый страничный режим) и мог реализовываться обычными микросхемами памяти при поддержке контроллера памяти чипсета, обеспечивая сокращение времени обращения к памяти для всех циклов пакета, кроме первого. Получающаяся при этом временная диаграмма пакетного цикла чтения представлена на рисунке:
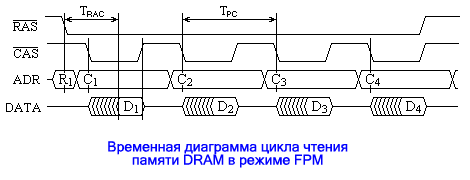 Как видно из рисунка, цикл чтения первого слова пакета выполняется так же, как и одиночное обращение. Второй и последующие циклы чтения оказываются короче первого из-за отсутствия фазы подачи адреса строки, и их длительность определяется минимально допустимым периодом следования импульсов CAS# – TPC (Page CAS Time). Соотношение длительностей первого и последующих циклов при частоте системной шины может достигать 5 : 3, откуда и обозначение 5-3-3-3, используемое как характеристика памяти (и чипсета) и указывающее, что первый из циклов пакета занимает по времени 5 циклов системной шины, а последующие – по 3 цикла. Длительность (низкого уровня) импульса CAS# определяется не только временем извлечения данных из памяти, но и временем удержания их на выходе микросхемы памяти. Последнее необходимо для фиксации прочитанных данных (контроллером памяти), так как данные присутствуют на выходе только до подъема сигнала CAS#. Поэтому следующей модификацией асинхронной динамической памяти стала память EDO (Extended Data Output – растянутый выход данных). В микросхеме EDO памяти на выходе был установлен буфер-защелка, фиксирующий данные после их извлечения из матрицы памяти при подъеме сигнала CAS# и удерживающий их на выходе до следующего его спада. Это позволило сократить длительность сигнала CAS# и соответственно цикла памяти, доведя пакетный цикл до соотношения с циклами системной шины 5-2-2-2. Временная диаграмма для режима EDO показана на рисунке, а сам этот режим иногда называют гиперстраничным (Hyper Page Mode):
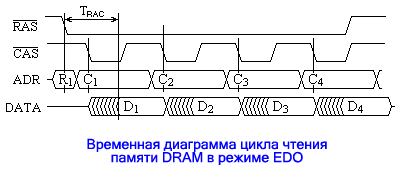 Впоследствии появилась и еще одна (последняя) модификация асинхронной DRAM – BEDO (Burst EDO – пакетная EDO память), в которой не только адрес строки, но и адрес столбца подавался лишь в первом цикле пакета, а в последующих циклах адреса столбцов формировались с помощью внутреннего счётчика. Это позволило ещё повысить производительность памяти и получить для пакетного цикла соотношение 5-1-1-1. Однако у производителей этот тип памяти не получил широкого распространения, т.к. на смену асинхронной памяти пришла синхронная – SDRAM. Синхронная динамическая память SDRAM Синхронная динамическая память обеспечивает большее быстродействие, чем асинхронная, при использовании аналогичных элементов памяти. Это позволяет реализовать пакетный цикл типа 5-1-1-1 при частоте системной шины 400 МГц и выше. (При этом нужно заметить, что в синхронной памяти обозначение из четырех чисел, разделенных дефисами, стало применяться в ином смысле, о чем будет указано ниже). Основные сигналы интерфейса SDRAM схожи с сигналами интерфейса асинхронной памяти. Главные их отличия сводятся к появлению ряда новых сигналов: - у памяти SDRAM присутствует синхросигнал CLK, по переднему фронту которого производятся все переключения в микросхеме. Кроме этого сигнала имеется также сигнал CKE (Clock Enable), разрешающий работу микросхемы при высоком уровне, а при низком – переводящий её в один из режимов энергосбережения. - В интерфейсе SDRAM имеются сигналы выбора банка BS0 и BS1 (Bank Select), позволяющие адресовать конкретные обращения в один из 4-х имеющихся в микросхемах SDRAM банков (массивов элементов) памяти. - Присутствуют сигналы DQM маски линий данных, позволяющие блокировать запись данных в цикле записи. - Имеет место специфическое использование одной из адресных линий A10 в момент подачи сигнала CAS#. Значение сигнала на этой линии задает способ подзаряда строки банка. В SDRAM памяти процессы синхронны, что позволяет более жестко упорядочить их во времени. Во-вторых, микросхемы SDRAM имеют внутреннюю мультибанковую организацию. Это позволяет применять приемы, повышающие пропускную способность памяти. В частности, можно прибегнуть к чередованию, или расслоению, (interleave) адресов. В общем случае процедура записи/чтения в SDRAM памяти выполняется в три этапа:
- сначала, при подаче сигнала RAS# происходит выбор нужной строки (выполняется активация банка). Именно за счет первого и последнего этапов и можно добиться ускорения работы памяти. Если очередное обращение к данному банку будет адресоваться к той же строке, то её можно не закрывать, что позволит не выполнять заново команду активации банка. Основные временные характеристики синхронной динамической памяти стали обозначать частотой синхронизации в мегагерцах, которой предшествовали символы PC (PC100, PC133, PC167), и тремя числами, разделяемыми дефисами, например, 2-2-2 или 3-2-2 (их обычно называют таймингами). Три числа означают минимальные времена, выраженные в количестве циклов синхронизации:
* первая цифра - между сигналами RAS# и CAS#, т.е. время tRCD, Синхронная динамическая память DDR и DDR2 SDRAM ..дальнейшее развитие синхронной динамической памяти пошло по пути повышения частоты синхронизации и скорости передачи данных. Первым шагом в этом направлении стала память DDR SDRAM, обеспечивающая двойную скорость передачи данных (DDR – Double или Dual Data Rate), в которой за один такт осуществляются две передачи данных – по переднему и заднему фронтам каждого синхроимпульса. Во всём остальном эта память работает аналогично обычной SDRAM памяти. Времена задержек CAS Latency для DDR SDRAM могут быть 2 и 2,5 такта, иногда встречаются даже и очень медленные схемы с 3-х цикловыми задержками. Ещё одним отличием DDR от SDRAM является организация буфера считываемых из матрицы данных. Поскольку можно организовать считывание целой строки матрицы, то в буфер возможно сразу считать двойную порцию данных, которую затем выдать из него с удвоенной скоростью. Дальнейшим развитием DDR SDRAM является стандарт DDR2. В нём обеспечивается учетверённая скорость передачи данных, за счёт удвоенной частоты работы буфера. Из-за более высокой частоты времена задержек tRCD, CAS Latency и tRP в таких микросхемах требуют большего количества циклов: 3, 4 и 5 – в зависимости от быстродействия и рабочей частоты. Микросхемы этого типа изготавливаются в других корпусах, используют более низкое напряжение питания и некоторые другие технологические особенности. Коммерческие названия DDR и DDR2 несколько различаются. Для DDR обычно указывают скорость передачи данных, что с учётом передачи за один раз 8 байтов данных даёт скорость (при 2-х передачах за цикл): - при частоте шины 133 МГц 2 x 133 x 8 = 2128 Мбайт/с, - при частоте 166 МГц 2 x 166 x 8 = 2656 Мбайт/с - при частоте 200 МГц 2 x 200 x 8 = 3200 Мбайт/сТакую память маркируют PC2100, PC2700 и PC3200 соответственно, причём этот ряд постоянно растёт.
Для DDR2 используется аналогичное обозначение с указанием в нём дополнительного числа 2. - при частоте 166 МГц 2 x 166 x 16 = 5312 Мбайт/с - при частоте 200 МГц 2 x 200 x 16 = 6400 Мбайт/сВременные характеристики (тайминги) для памяти DDR и DDR2 обозначают четверкой чисел, первые три из которых означают времена tRCD, CAS Latency и tRP, а четвертое (которое редко указывалось у памяти с одинарной скоростью передачи) - минимальное время tRC цикла, между подачей сигнала RAS# и началом регенерации строки. Например, тайминги 3-3-3-9, указанные для модуля (микросхемы) памяти DDR2, выражают названные времена в циклах синхронизации. Понятно, что чем меньше эти числа, тем более быстрой является память. Дальнейшим развитием SDRAM является стандарт DDR3, в котором обеспечивается восьмикратная скорость передачи данных по отношению к частоте работы самих элементов памяти. Известна также и используемая в видеокартах память DDR5. SRAM. Статические ЗУ с произвольным доступом В статических ЗУ (Static Random Access Memory – SRAM) в качестве элемента памяти используется триггер, что, конечно, сложнее, чем конденсатор с транзисторным ключем динамического ЗУ. Поэтому статические ЗУ обладают меньшей плотностью хранения информации. Однако триггер со времён первых компьютеров был и остается самым быстродействующим элементом памяти! Поэтому статическая память позволяет достичь наибольшего быстродействия, обеспечивая время доступа в десятые доли наносекунд, что и обусловливает её использование в высших ступенях памяти – кэш-памяти всех уровней. Главными недостатками статической памяти являются её относительно высокие стоимость и энергопотребление. Конечно, в зависимости от используемой технологии, память будет обладать различным сочетанием параметров быстродействия и потребляемой мощности. Например, статическая память, изготовленная по КМОП-технологии (CMOS память), имеет низкую скорость доступа, со временем порядка 100 нс, но зато отличается очень малым энергопотреблением. В компьютерах такую память применяют для хранения конфигурационной информации компьютера. Питание такой памяти осуществляется от небольшой батарейки, которая может служить несколько лет. Основными разновидностями статической памяти (SRAM) являются асинхронная (Asynchronous), синхронная-пакетная (Synchronous Burst) и синхронная конвейерно-пакетная (Pipeline Burst) память. Первой появилась асинхронная память. Интерфейс этой памяти включает шины данных, адреса и управления. В состав сигналов шины управления входят:
CS# (Chip Select) – сигнал выбора микросхемы; WE# (Write Enable) – сигнал разрешения записи; OE# (Output Enable) – сигнал включения выходов для выдачи данных.Все сигналы управления инверсные, т.е. их активный (вызывающий соответствующее действие) уровень - низкий. При единичном значении сигнала OE# выход микросхемы переходит в состояние высокого выходного сопротивления. Временные диаграммы циклов чтения и записи приведены на рисунке, и не требуют особых пояснений:
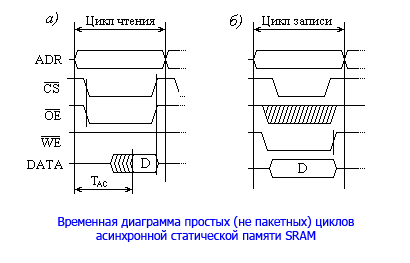 Время доступа tAC у типовых микросхем составляет порядка 10 нс. Поэтому реально такие микросхемы могут работать на частотах, близких к частоте системной шины, только если эти частоты не превышают 66 МГц. Несколько позже появилась синхронная пакетная статическая память (SBSRAM), ориентированная на выполнение пакетного обмена информацией, который характерен для кэш-памяти. Эта память включает в себя внутренний счётчик адреса, предназначенный для перебора адресов пакета, и использует сигналы синхронизации CLK, как и синхронная DRAM память. Для организации пакетного обмена, помимо имеющихся у асинхронной памяти управляющих сигналов CS#, OE# и WE#, в синхронную память также введены сигналы ADSP# (Address Status of Processor) и CADS# (Cache Address Strobe), сопровождающие передачу адреса нового пакета, а также сигнал продвижения на следующий адрес пакета ADV# (Advance). Пакетный цикл всегда предусматривает передачу четырех элементов, т.к. внутренний счётчик имеет всего 2 бита, причём перебор адресов в пределах пакета может быть последовательным или с расслоением (чередованием) по банкам (при использовании процессоров семейства x86). Следующим шагом в развитии статической памяти явилась конвейерно-пакетная память PBSRAM, обеспечивающая более высокое быстродействие, чем SBSRAM. В неё были введены дополнительные внутренние буферные регистры данных адреса (здесь можно провести аналогию с EDO DRAM памятью), а в ряде модификаций предусмотрена возможность передачи данных на двойной скорости по переднему и заднему фронтам синхросигнала и используются сдвоенные внутренние тракты записи и чтения. Это позволило получить время обращения порядка 2-3 нс и обеспечить передачу данных пакета без задержек на частотах шины более 400 Мгц.
Кэш-память процессораЗадачи кэш-памяти Кэш (сверхоперативная память) - представляет собой высокоскоростное ЗУ небольшой ёмкости для временного хранения данных. В задачи кэша входит:
- обеспечение быстрого доступа к интенсивно используемым данным; - согласование интерфейсов процессора и контроллёра памяти; - упреждающая загрузка данных; - отложенная запись данных.Обеспечение быстрого доступа к интенсивно используемым данным. Архитектурно кэш-память расположена между процессором и ОЗУ и охватывает всё (реже - часть) адресное пространство.
+---------------------+
| Оперативная память |
+---------------------+
|
+------------------+ +--------------+
| Кэш-контроллёр +---+ Кэш-память |
+------------------+ +--------------+
|
+-------------------------+
| Центральный процессор |
+-------------------------+
Перехватывая запросы к основной памяти, кэш-контроллёр смотрит: есть-ли действительная (valid) копия затребованных данных в кэше. Если такая копия там есть, то данные извлекаются из сверхоперативной памяти и происходит так называемое кэш-попадание - cache hit. В противном случае говорят о промахе - cache miss, и тогда запрос данных переадресуется к основной оперативной памяти.Для достижения наивысшей производительности кэш-промахи должны происходить как-можно реже. Учитывая, что ёмкость кэш-памяти намного меньше ёмкости ОЗУ, добиться этого не так-то просто! В обязанности кэш-контроллёра в первую очередь входит накопление в сверхоперативной памяти действительно нужных данных и своевременное удаление оттуда всякого "мусора" - данных, которые более не понадобятся. Поскольку кэш-контроллёр не имеет представления о назначении обрабатываемых данных, эта задача требует нехилого искусственного интеллекта. Но, увы! Кэш-контроллёры интеллектом не обременены и слепо действуют по одному из нескольких шаблонов, называемых стратегиями кэширования. Согласование интерфейсов процессора и контроллера памяти. "Ячейка памяти" (в понятии современных процессоров) представляет собой, как правило, байт (FF), слово (FF FF) или двойное слово (FF FF FF FF). С другой стороны, минимальной порцией обмена с физической оперативной памятью является пакет, состоящий как минимум из четырех 64-разрядных ячеек (32 байта). Здесь можно провести аналогию с оптовой торговлей - производитель не отпускает товар по штукам и если нам, положим, требуется один карандаш, мы всё-равно вынуждены приобретать целую упаковку. Естественно, пока остальные карандаши не будут реально востребованы, их необходимо где-то хранить. Решение: извлечь один-единственный карандаш из упаковки и выбросить остатки слишком нерационально, поэтому здесь не рассматривается. Тем более, что подходящее хранилище для пакетов данных у нас есть - это кэш. Получив пакет данных со склада (загрузив их из ОЗУ) кэш позволяет процессору впоследствии обрабатывать эти данные с любой разрядностью. Именно этим, кстати, объясняется выбранная стратегия загрузки данных. Кэш-контроллёр вынужден помещать в сверхоперативную памяти все ячейки, к которым происходит обращение, уже хотя бы потому, что выкидывать их, как карандаши в приведенном выше примере, было бы крайне нерационально. Упреждающая загрузка данных. Существует несколько стратегий загрузки данных из ОЗУ в кэш-память. Простейший алгоритм загрузки, называемый загрузкой по требованию (on demand), предписывает обращаться к ОЗУ только после того, как затребованных процессором данных не окажется в кэше (кэш-промах). Использование такой стратегии приводит к тому, что в кэш попадают действительно нужные нам данные, однако при первом обращении к ячейке, процессору придётся очень долго ждать (около 20 тактов системной шины), что не есть хорошо! Стратегия спекулятивной (speculative) загрузки, напротив, предписывает помещать данные в кэш задолго то того, как к ним произойдет обращение. Откуда-же кэш-контроллёру знать, какие ячейки потребуются процессору в ближайшем будущем? Знать этого он конечно-же не может, но почему-бы не попробовать просто угадать? Алгоритмы угадывания делятся на интеллектуальные и неинтеллектуальные. Типичный пример неинтеллектуального алгоритма - опережающая загрузка. Исходя из того, что данные из ОЗУ обрабатываются последовательно, кэш-контроллёр, перехватив запрос на чтение первой ячейки загружает некоторое количество ячеек, последующих за ней. Если данные действительно обрабатываются последовательно, то остальные запросы процессора будут выполнены практически мгновенно, ведь запрошенные ячейки уже присутствуют в кэше! Следует заметить, что стратегия опережающей загрузки возникает уже в силу необходимости согласования разрядности ОЗУ и процессора. Интеллектуальный кэш-контроллёр предсказывает адрес следующей-запрашиваемой ячейки не по слепому шаблону, а на основе анализа предыдущих обращений. Исследуя последовательность кэш-промахов, контроллёр пытается установить, какой зависимостью связны её элементы и, если это ему удаётся, предвычисляет её последующие члены. Отложенная запись данных. Наличие временного хранилища данных позволяет накапливать записываемые данные и затем (дождавшись освобождения системой шины), выгружать их в ОЗУ "одним махом". Это ликвидирует задержки и значительно увеличивает производительность подсистемы памяти. В x86-процессорах механизм отложенной записи реализован, начиная с Pentium и AMD K5. Более ранние модели были вынуждены непосредственно записывать в основную память каждую модифицируемую ячейку, что серьезно ограничивало их быстродействие. К счастью, сегодня такие процессоры практически не встречаются и об этой проблеме уже можно забыть. Стратегии кэширования Стратегия помещения данных в кэш-память представляет собой алгоритм, определяющий - стоит-ли помещать копию запрошенных данных в кэш или нет? Процессоры класса Pentium и AMD (от K5 и выше) помещают в кэш все данные, к которым хотя бы однократно происходит обращение. Поскольку мы не можем сохранить в кэше содержимое всей ОЗУ, то рано или поздно кэш заполняется по самую макушку. Настанет время, когда для помещения новой порции нам придётся выкинуть из кэша что-нибудь "ненужное". В современных ОС чаще всего используются следующие стратегии кэширования: вталкивания, размещения и выталкивания. В основном применяется стратегия "выталкивания". Цель этой стратегии – решить, какую страницу (или сегмент) следует удалить из кэша, чтобы освободить место для помещения поступающей страницы. Стратегия "выталкивания" имеет несколько алгоритмов: Принцип оптимальности (ОРТ) Принцип оптимальности говорит о том, что для обеспечения оптимальных характеристик следует заменять ту страницу, к которой в дальнейшем не будет новых обращений в течение наиболее длительного времени. Можно, конечно, продемонстрировать, что подобная стратегия действительно оптимальна, однако реализовать её, естественно, нельзя, поскольку мы не умеем предсказывать будущее. Выталкивание случайной страницы (RANDOM) ..можно пойти по простому пути – выбирать случайную страницу. В этом случае все страницы, находящиеся в кэш, могут быть выбраны для выталкивания с равной вероятностью, в том числе даже следующая страница к которой будет производиться обращение (и которую, естественно, удалять из памяти наиболее нецелесообразно). Поскольку подобная стратегия по сути как-бы рассчитана на “слепое” везение, в реальных системах она применяется редко. Выталкивание первой пришедшей страницы (FIFO) При выталкивании страниц по принципу FIFO мы присваиваем каждой странице (в момент поступления в основную память) временную метку. Когда появляется необходимость удалять из основной памяти какую-нибудь страницу, мы выбираем ту, которая находилась в памяти дольше других. Интуитивный аргумент в пользу подобной стратегии кажется весьма весомым, а именно: у данной страницы уже были возможности “использовать свой шанс”, и пора дать подобные возможности и другой странице. К сожалению, стратегия FIFO с достаточно большой вероятностью будет приводить к замещению активно используемых страниц, поскольку тот факт, что страница находится в основной памяти в течение длительного времени, вполне может означать, что она постоянно в работе. Выталкивание дольше всего не использовавшейся страницы (LRU) Эта стратегия предусматривает, что для выталкивания следует выбирать ту страницу, которая не использовалась дольше других. Здесь мы исходим из эвристического правила, говорящего о том, что недавнее прошлое – хороший ориентир для прогнозирования ближайшего будущего. Стратегия LRU требует, чтобы при каждом обращении к странице её временная метка обновлялась. Выталкивание реже всего используемой страницы (LFU) Одной из близких к LRU стратегий является стратегия, согласно которой выталкивается наименее часто (наименее интенсивно) использовавшаяся страница (LFU). Здесь мы контролируем интенсивность использования каждой страницы. Выталкивается та страница, которая наименее интенсивно используется или обращения к которой наименее часты. Подобный подход опять-таки кажется интуитивно оправданным, однако в то же время велика вероятность того, что удаляемая страница будет выбрана нерационально. Таким образом, практически любой метод выталкивания страниц, по-видимому, не исключает опасности принятия нерациональных решений. Это действительно так просто потому, что мы не можем достаточно точно прогнозировать будущее. В связи с этим необходима такая стратегия выталкивания страниц, которая обеспечивала-бы принятие рациональных решений. Выталкивание не использовавшейся в последнее время страницы (NUR) Один из распространенных алгоритмов, близких к стратегии LRU и характеризующихся малыми задержками – это алгоритм выталкивания страницы, не использовавшейся в последнее время (NUR). К страницам, которая в последнее время не использовались, вряд ли будут обращения и в ближайшем будущем, так что их можно заменять на вновь поступающие страницы. Таким образом, решение о выталкивании страниц можно принимать основываясь на нескольких аспектах:
- количестве обращений к каждой порции данных В современных процессорах семейства x86 встречаются исключительно стратегии FIFO и LRU, частотный-же анализ, ввиду сложности его реализации, в них не используется.
Организация кэшаДля упрощения взаимодействия с ОЗУ, кэш-контроллёр оперирует не байтами, а блоками данных, соответствующих размеру пакетного цикла чтения/записи. Программно кэш-память представляет собой совокупность блоков данных фиксированного размера, называемых кэш-линейками (cache-line) или кэш-строками.Каждая кэш-строка полностью заполняется/выгружается за один пакетный цикл чтения и всегда заполняется/выгружается целиком. Даже если процессор обращается к одному байту памяти, кэш-контроллёр инициирует полный цикл обращения к основной памяти и запрашивает весь блок целиком. Причем адрес первого байта кэш-линейки всегда кратен размеру пакетного цикла обмена. Другими словами, начало кэш-линейки всегда совпадает с началом пакетного цикла. Поскольку объём кэша много меньше объема ОЗУ, то каждой кэш-линейке соответствует множество ячеек кэшируемой памяти, а отсюда с неизбежностью следует, что приходится сохранять не только содержимое кэшируемой ячейки, но и её адрес. Для этой цели каждая кэш-линейка имеет специальное поле, называемое тегом (TAG). В теге хранится линейный и/или физический адрес первого байта кэш-линейки. Т.е. кэш-память фактически является ассоциативной памятью (associative memory) по своей природе. В некоторых процессорах (например, в младших моделях процессоров Pentium) используется только один набор тегов, хранящих физические адреса. Это удешевляет процессор, но для преобразования физического адреса в линейный требуется, по меньшей мере, один дополнительный такт, что снижает производительность. Другие-же процессоры (например, AMD K5) имеют два набора тегов - для хранения физических и линейных адресов, соответственно. К физическим тегам процессор обращается лишь в двух ситуациях: при возникновении кэш-промахов и при поступлении запроса от внешних устройств (в т.ч. и других процессоров в многопроцессорных системах). Во всех остальных случаях используются исключительно линейные теги, что предотвращает необходимость постоянного преобразования адресов. Таким образом, полезная ёмкость кэш-памяти всегда меньше её физической ёмкости, т.к. некоторая часть ячеек расходуется на создание тегов, совокупность которых так и называется - "память тегов" (остальные ячейки образуют "память кэш-строк"). Следует заметить, что производители всегда указывают именно полезную, а не полную ёмкость кэш-памяти, поэтому за память, "отъедаемую" тегами, потребителям можно не волноваться. Существует две разновидности кэш-памяти - блокируемая и неблокируемая кэш-память: - Блокируемая кэш-память, как и следует из её названия, блокирует доступ к кэшу после всякого кэш-промаха. Независимо от того, присутствуют-ли запрашиваемые данные в сверхоперативной памяти или нет, пока кэш-строка, вызвавшая промах, не будет целиком загружена/выгружена, кэш не сможет обрабатывать никаких других запросов. В настоящее время блокируемая кэш-память практически не используется, поскольку при частых кэш-промахах она работает крайне непроизводительно. - Неблокируемая кэш-память, напротив, позволяет работать с кэшем параллельно с загрузкой/выгрузкой кэш-строк. То есть, кэш-промахи не препятствует кэш-попаданиям. И это - хорошо! Несмотря на то, что неблокируемая кэш-память имеет значительно большую аппаратную сложность (а, значит, и стоимость), она широко используется в старших процессорах семейства x86, как впрочем и во многих других современных процессорах. Понятие ассоциативности кэша Проследим по шагам, как работает кэш. Вот процессор обращается к ячейке памяти с адресом XY. Кэш-контроллёр, перехватив это обращение, первым делом пытается выяснить - присутствуют ли запрошенные данные в кэш-памяти или нет? Вот тут-то и начинается самое интересное! Легко показать, что проверка наличия ячейки в кэш-памяти фактически сводится к поиску соответствующего диапазона адресов в памяти тегов. В зависимости от архитектуры кэш-контроллёра, просмотр всех тегов осуществляется либо параллельно, либо последовательно. Параллельный поиск, конечно, чрезвычайно быстр, но и сложен в реализации. Последовательный-же перебор тегов при большом их количестве крайне непроизводителен. Кстати, а сколько у нас тегов? Правильно - ровно столько, сколько и кэш-строк. Так, в частности, в 32-килобайтном кэше насчитывается 1024 тегов (32-разрядная система). Стоп! Сколько времени потребует просмотр 1024 тегов?! Даже если несколько тегов будут просматриваться за один такт, поиск нужной нам линейки растянется на сотни тактов, что "съест" весь выигрыш в производительности. Нет уж, какая динамическая память не тормозная, а к ней обратится побыстрее будет, чем сканировать кэш... Но ведь кэш все-таки работает! Спрашивается, как? Оказывается (и этого следовало ожидать), что последовательный перебор - не самый продвинутый алгоритм поиска. Существуют и более элегантные решения. Рассмотрим два наиболее популярные из них. В кэше прямого отображения проблема поиска решается так... Пусть каждая ячейка памяти соответствует не любой, а одной, строго-определённой строке кэша. В свою очередь, каждой строке кэша будет соответствовать не одна, а множество ячеек кэшируемой памяти, но опять-таки, не любых, а строго определенных. Пусть наш кэш состоит из четырёх строк, тогда (см.рис) первый пакет кэшируемой памяти связан с первой строкой кэша, второй - со второй, третий - с третьей, четвертый - с четвертой, а пятый - вновь с первой:
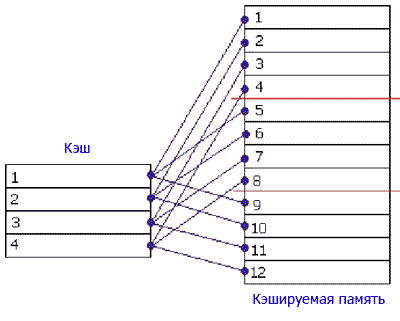 Таким образом, чтобы узнать - присутствует искомая ячейка в кэш-памяти или нет, достаточно просмотреть один-единственный тег соответствующей кэш-линейки, для вычисления номера которого требуется совершить всего 3 арифметические операции. Необходимость просматривать все теги в этой схеме естественным образом отпадает. Да, отпадает, но возникает другая проблема. Задумайтесь, что произойдет, если процессор попытается последовательно обратиться ко 2-ой, 6-ой и 10-ой ячейкам кэшируемой памяти? Правильно - несмотря на то, что в кэше будет полно свободных строк, каждая очередная ячейка будет вытеснять предыдущую, т.к. все они жёстко закреплены именно за второй строкой кэша. В результате кэш будет работать максимально неэффективно, полностью вхолостую (trashing). Программист, заботящийся об оптимизации своих программ, должен организовать структуры данных так, чтобы исключить частое чтение ячеек памяти с адресами, кратными размеру кэша. Понятное дело - такое требование не всегда выполнимо и кэш прямого отображения обеспечивает далеко не лучшую производительность. Поэтому, в настоящее время он практически нигде не встречается и полностью вытеснен наборно-ассоциативной сверхоперативной памятью. Наборно-ассоциативный кэш состоит из нескольких независимых банков, каждый из которых представляет собой самостоятельный кэш прямого отображения. Взгляните на рисунок. Каждая ячейка кэшируемой памяти может быть сохранена в любой из двух строк кэш-памяти. Допустим, процессор читает 6 и 10-ую ячейку кэшируемой памяти. Шестая ячейка идет во вторую строку первого банка, а десятая - во вторую строку следующего банка, т.к. первый уже занят
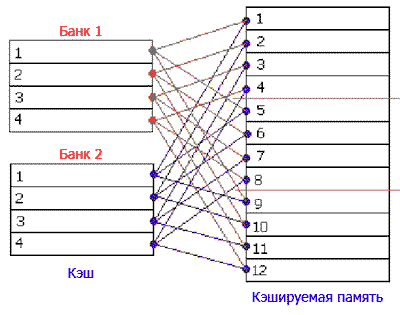 Количество банков кэша и называют его ассоциативностью (way). Здесь видно, что с увеличением степени ассоциативности, эффективность кэша существенно возрастает. В идеале, при наивысшей степени дробления в каждом банке будет только одна линейка и тогда любая ячейка кэшируемой памяти сможет быть сохранена в любой строке кэша. Такой кэш называют полностью ассоциативным кэшем или просто ассоциативным кэшем. Ассоциативность кэш-памяти, используемой в современных персональных компьютеров колеблется от двух (2-way cache) до восьми (8-way cache): Processors Information ********************************************************** Name Intel Pentium 4 531 Specification Intel(R) Pentium(R) 4 CPU 3.00GHz L1 Data cache 16 KBytes, 8-way set associative, 64-byte line size L2 cache 1024 KBytes, 8-way set associative, 64-byte line size ********************************************************** Политика записи и продержка коггерентности Если бы ячейки памяти ОЗУ были доступны только на чтение, то их скэшированная копия всегда совпадала-бы с оригиналами. Возможность записи рождает следующие проблемы: во-первых, кэш-контроллёр должен отслеживать модификацию ячеек кэш-памяти, а во-вторых, необходимо как-то отслеживать обращения всех периферийных устройств к ОЗУ (включая остальные микропроцессоры в многопроцессорных системах, HDD и т.д). В противном случае мы рискуем считать совсем не то, что записывали! Кэш-контроллёр обязан обеспечивать коггерентность (coherency) - согласованность кэш-памяти с ОЗУ. Допустим, к некоторой ячейке памяти (уже модифицированной в кэше, но ещё не выгруженной в ОЗУ) обращается периферийное устройство. Кэш-контроллёр должен немедленно обновить ОЗУ, иначе оттуда прочитаются "старые" данные. Аналогично, если периферийное устройство (другой процессор) модифицирует основную память, например посредством DMA (прямой доступ к памяти), кэш-контроллёр должен выяснить, загружены-ли модифицированные ячейки в его кэш-память и, если да - обновить их. Поддержка коггерентности - задача серьёзная. Самое простое (но не самое лучшее) решение, мгновенно приходящее на ум - кэшировать ячейки ОЗУ в режиме "только чтение", а запись осуществлять напрямую, минуя кэш, сразу в основную память. Это так называемая сквозная (Write True) политика. Сквозная политика легка в аппаратной реализации, но крайне неэффективна. Частично компенсировать задержки обращения к памяти помогает буферизация. Записываемые данные на первом этапе попадают не в основную память, а в специальный буфер записи (store/write buffer), размером порядка 64 байт. Там они накапливаются до тех пор, пока буфер целиком не заполнится, а затем всё содержимое буфера записывается в память "одним скопом". Такой режим сквозной записи с буферизацией (Write Combining) значительно увеличивает производительность системы, но решает далеко не все проблемы. В частности, значительная часть процессорного времени по-прежнему расходуется именно на выгрузку буфера в ОЗУ. Тем более обидно, что в подавляющем большинстве компьютеров установлен всего один процессор и именно он, а не периферия, интенсивнее всех работает с памятью. Более сложный (но и совершенный!) алгоритм реализует обратная политика записи (Write Back), до минимума сокращающая количество обращений к памяти. Для отслеживания операций модификации, с каждой ячейкой кэш-памяти связывается специальный флаг, называемый флагом состояния. Если кэшируемая ячейка была модифицирована, то кэш-контроллёр устанавливает соответствующий ей флаг в грязное (dirty) состояние. Когда периферийное устройство обращается к памяти, кэш-контроллёр проверяет, находится-ли соответствующий адрес в кэш-памяти и если да, он глядя на флаг, определяет: грязная она или нет? Грязные ячейки выгружаются в ОЗУ, а их флаг устанавливается в состояние "чисто" (clear). Аналогично при замещении старых кэш-строк новыми, кэш-контроллёр в первую очередь стремится избавиться от чистых кэш-строк, т.к. они могут быть мгновенно удалены из кэша без записи в основную память (ОЗУ). И только если все строки грязные - выбирается одна, наименее ценная (с точки зрения политики замещения данных) и "сбрасывается" в основную память, освобождая место для новой "чистой" строки:
[Свойства кэша L1:]
Тип Внутренний
Статус Разрешено
Режим работы Write-Back
Максимальный объём 16 Кб
Установленный объём 16 Кб
Текущий тип SRAM Synchronous
[Свойства кэша L2:]
Тип Внутренний
Статус Разрешено
Режим работы Write-Back
Максимальный объём 2048 Кб
Установленный объём 1024 Кб
Текущий тип SRAM Synchronous
Управление памятьюРежимы работы процессоровПроцессоры могут работать в различных режимах. Под термином "режим" подразумевается способы, которым процессор создает (и обеспечивает) для себя рабочую среду. Режим работы процессора задает способ адресации к ОЗУ, и способ управления отдельными задачами. Процессоры персональных компьютеров могут работать в трех режимах: реальном, защищенном, виртуальном. Реальный режим. Первоначально машины IBM могли адресовать только 1 Мбайт ОЗУ. Это решение продолжало соблюдаться и в последующее время — в каждом компьютере следующего поколения процессор должен был уметь работать в режиме совместимости с процессором Intel 8086. Этот режим назвали "реальным". Когда процессор работает в реальном режиме, он может обращаться к памяти только в пределах 1 Мбайт и не может использовать 32/64-разрядные операции. Процессор попадает в реальный режим сразу-же после запуска. В реальном режиме работает только DOS и стандартные DOS-приложения, режим - однопользовательский, исполнительный адрес всегда соответствует физическому. Защищённый режим. Начиная с процессоров Intel 80286 и компьютеров типа IBM PC/AT, появляется "защищённый режим". Это более мощный режим работы процессора по сравнению с реальным режимом. Он используется в современных многозадачных ОС. Защищенный режим имеет много преимуществ:
- доступна вся системная память (не существует предела 1 Мбайт). Каждая выполняемая на компьютере программа имеет свою собственную область памяти, которая защищена от доступа со стороны других программ. Когда какая-либо программа пытается обратиться по неразрешённому для неё адресу памяти, генерируется ошибка защиты памяти. Все современные ОС используют защищенный режим, включая Windows и Linux. Даже DOS (обычно работающая в реальном режиме) может использовать доступ к памяти защищенного режима с помощью программного интерфейса DPMI (DOS Protected Mode Interface — интерфейс защищённого режима). Этот интерфейс используется компьютерными играми и другими программами под DOS для того, чтобы преодолеть барьер в 640 Кбайт основной памяти DOS. Виртуальный режим. Защищенный режим используют графические многозадачные ОС, такие как Windows. Иногда возникает необходимость выполнения DOS-программ в среде Windows. Но DOS-программы работают в реальном режиме, а не в защищённом. Для решения этой проблемы был разработан "виртуальный режим". Этот режим эмулирует/имитирует реальный режим, необходимый для работы DOS-программ, внутри защищенного режима. Операционные системы защищённого режима (такие как Windows) могут создавать несколько машин виртуального режима, при этом каждая из них будет работать так, как-будто она одна использует все ресурсы компьютера. Каждая виртуальная машина получает в свое распоряжение 1 Мбайтное адресное пространство, образ реальных программ BIOS и т.п. Виртуальный режим используется при работе в DOS-окне или при запуске DOS-игр в операционной системе Windows. При запуске на компьютере DOS-приложения операционная система Windows создает виртуальную DOS-машину, в которой выполняется это приложение.
Адресная карта памяти..некоторая терминология, принятая в MS-DOS для обозначения областей памяти.Вся память делится на 3 части: стандарная, верхняя, дополнительная. В свою очередь дополнительная память делится ещё на 2 части - HMA и XMS:
+------------------------------+ --
| | \
| | \
| Выше 1088 Кбайт, |
| дополнительная память | Выше 1024 Кбайт,
| по стандарту XMS | расширенная память (EMS)
| |
+- - - - - - - - - - - - - - - +
| 1024 - 1088 Кбайт, | /
| высокая память НМА | /
+------------------------------+ --
| 640 - 1024 кбайт, |
| область верхней памяти UMA |
| |
+------------------------------+
| 0 - 640 кбайт, |
| стандартная память |
+------------------------------+
Cтандартная память (conventional memory) представляет собой "нижние" 640 Кбайт ОЗУ. Для использования этой памяти не нужны никакие дополнительные драйвера, поскольку DOS изначально создана для работы в адресах 0-640 Кбайт.Областью верхней памяти (Upper Memory Area - UMA) называется часть ОЗУ, находящаяся между адресами 640 и 1024 Кбайт. Для использования памяти выше 640 Кбайт существуют специальные программы/драйверы - EMM386.EXE, HIMEM.SYS и др., которые позволяют использовать свободные участки верхней памяти, для загрузки резидентных программ и устанавливаемых драйверов внешних устройств.
Дополнительной памятью (extended memory) называется память выше 1024 Кбайт. Согласно общепринятой спецификации XMS 3.0 (eXtended Memory Specification), дополнительная память делится на две области (см.рис) — область высокой памяти объёмом 64 Кбайт (High Memory Area - HMA) и собственно дополнительную память, которую обычно называют XMS. Драйвер HIMEM.SYS отводит часть области верхней памяти для того, чтобы поочередно отображать в неё требуемые участки расширенной памяти. Каждый-непрерывный участок расширенной памяти называется страницей (page), а "окно" в области UMA, через которое процессор просматривает содержимое страниц расширенной памяти - страничным блоком. Схематично этот процесс представлен на следующем рисунке:
640-1024 Кбайт,
область верхней памяти
/
/
+----------------+ +--------------+
| Область BIOS | |xxxxxxxxxxxxxx|
| | +--------------+
+----------------+ +->| Страница |
|xxxxxxxxxxxxxxxx|\ / +--------------+
|xxxxxxxxxxxxxxxx| \ / |xxxxxxxxxxxxxx|
|----------------| \ / +--------------+
| Страничный |---\/----->| Страница |
| блок | /\ +--------------+
|----------------| / \ |xxxxxxxxxxxxxx|
|xxxxxxxxxxxxxxxx| / \ +--------------+
|xxxxxxxxxxxxxxxx|/------\-->| Страница |
+----------------+ \ +--------------+
| | | |xxxxxxxxxxxxxx|
| Область | | +--------------+
| видеопамяти | +->| Страница |
+----------------+ +--------------+
\
\ Область
расширенной памяти (EMS)
Расширенная память специальным образом отображается на верхнюю область памяти от 640 до 1024 Кбайт. Эт способ увеличения объёма доступной памяти называется "отображаемой памятью". Он позволяет адресовать большой объём памяти, не выходя за пределы первого мегабайта.Нижняя часть памяти выделена для трёх важных объектов, влияющих на работу всего компьютера. Первым из них является таблица векторов прерываний, определяющих местонахождение процедур обработки прерываний. Таблица занимает первые 1024 байта памяти и содержит 256 векторов. Диапазон абсолютных адресов: 0 - 400h. (400h = 1024d) Вторая область служит рабочим пространством для процедур ROM-BIOS, который осуществляет общее управление компьютером. Здесь находится буфер, в котором хранятся клавишные действия пользователя, инфа об имеющейся памяти, список основного оборудования и индикатор режима работы дисплея. Для области данных ROM-BIOS выделено 256 байтов с абсолютными адресами от 400Н до 500Н. В качестве рабочей области для DOS зарезервирована третья часть нижней памяти компьютера, состоящая из 256 байтов с адресами от 500Н до 600Н. Основная рабочая память, занимающая первые 10 страничных блоков (0 - 9), предназначена для программ и их данных. Её часто называют областью пользовательской памяти. Когда говорят о ёмкости памяти компьютера, обычно имеют в виду именно пользовательскую память. Вся установленная память образует смежную область от блока 0 до фактического конца памяти. Ёмкость памяти, на которую рассчитана стандартная архитектура 8086/DOS, составляет 1 Мбайт, из которых для программ и данных доступны только 640 Кбайт. Основная проблема - резервирование адресов от 640 Кбайт до 1 Мбайт (и наличие тысяч приложений, рассчитанных на это) остаётся главным недостатком DOS. Иногда подобные проблемы возникают даже в управляющих программах Windows, поскольку они опираются на DOS.
Сегментная и линейная адресацияВо избежания путаницы, рассмотрим понятия сегментного и линейного адреса. Появление сегментных адресов связано с внутренней архитектурой процессоров Intel, в которых инфа о сегменте и смещении хранится в отдельных регистрах. Принцип адресации памяти у этих процессоров довольно прост..Представьте себе 5-тиэтажку (0-4), на каждом этаже которой по 10 квартир (0-9). Сегментом считается каждый "этаж", т.е. любая группа из 10 квартир с последовательными номерами. Каждому сегменту/этажу присвоен порядковый номер из двух цифр (00-10-20-30-40). Например, адрес сегмента 4 соответствует квартире с номером 40. ..также, можно задать и смещение в диапазоне от 0 до 9. Допустим, нам нужна квартира 46! В виде [сегмент]:[смещение] это будет - 0040:0006. ...Но можно сказать и иначе - 0030:0016 или 0010:0036. Используя различные сегменты и смещения, можно получить один и тот-же адрес:
0 1 2 3 4 5 6 7 8 9
0000:0000 . . . . . . . . . .
0010:0000 . . . . . . . . . .
0020:0000 . . . . . . . . . .
0030:0000 . . . . . . . . . .
0040:0000 . . . . . . x . . .
Описанным способом организуется адресация памяти в процессорах фирмы "Intel". Обратите внимание, что все разряды чисел, выражающих [сегмент]:[смещение] перекрываются, за исключением первого и последнего. Если сложить эти числа с соответствующим сдвигом, можно получить линейный адрес.Линейный адрес не делится на две составляющих. Это обычно число, а не сумма двух чисел. Например, на плате адаптера может быть установлена м/с ROM на 16 Кбайт, ячейкам которой присвоены адреса D4000-D7FFF. В формате сегмент:смещение эти адреса можно представить так: D400:0000-D700:0FFF. Поскольку эти составляющие перекрываются, то конечный адрес можно представить различными способами:
D000:7FFF = D7FFF
или
D700:0FFF = D7FFF
или
D7F0:00FF = D7FFF
или
D7FF:000F = D7FFF
или
D500:2FFF = D7FFF
или
D6EE:111F = D7FFF
и т.д.Итак, задавать адрес можно различными способами, но лучше всего записывать его в линейной форме (D7FFF), а из всего разнообразия комбинаций [сегмент]:[смещение] следует использовать D000:7FFF. Указав в сегментной части адреса макс.кол-во нулей, можно упростить его восприятие и сразу видна его связь с полным линейным адресом. Из приведённых примеров понятно, почему линейный адрес является 5-тиразрядным, хотя сегмент и смещение - 4-хразрядные числа.
Понятие виртуальной памятиВ многозадачных системах каждому процессу отводится некоторый непрерывный набор адресов. В простейшем случае макс.объём адресного пространства (выделяемого процессу) меньше объёма ОЗУ. Таким образом, процесс может заполнить своё адресное пространство и для его размещения в памяти будет достаточно места.Но что произойдет, если адресное пространство процесса превышает объём ОЗУ? На первых компьютерах такой процесс неизменно терпел-бы крах. В наше время существует технология виртуальной памяти, согласно которой ОС хранит часть адресного пространства в ОЗУ, а часть на диске, по необходимости меняя их фрагменты местами. По сути, операционная система создает абстракцию адресного пространства в виде набора адресов, на которые может ссылаться процесс. Адресное пространство — это набор адресов, который может быть использован процессом для обращения к памяти, причём у каждого процесса имеется своё собственное адресное пространство. Понятие адресного пространства имеет весьма универсальный характер и появляется во множестве контекстов. Например, адреса портов ввода-вывода простираются от 0 до 65535 (FFFF), в то время как ОЗУ занимает адреса от 0 до 4294967295 (0xFFFFFFFF):
Память 00000000-0009FFFF Исключительный Системная плата Память 000A0000-000BFFFF Общий NVIDIA GeForce 6600 GT Память E0000000-EFFFFFFF Исключительный NVIDIA GeForce 6600 GT Память FA002000-FA0020FF Исключительный Realtek AC'97 Audio Память FFF00000-FFFFFFFF Исключительный Системная плата Порт 0000-000F Исключительный Контроллер прямого доступа к памяти (DMA) Порт 0020-0021 Исключительный Программируемый контроллер прерываний Порт 0070-0073 Исключительный CMOS и часы Порт 0170-0177 Исключительный Вторичный канал IDE Порт 0378-037F Исключительный Порт принтера (LPT1) Порт 03B0-03BB Общий NVIDIA GeForce 6600 GT Порт 9000-90FF Исключительный ESS Allegro PCI Audio (WDM) Порт C400-C43F Исключительный Realtek AC'97 AudioНемного сложнее понять, как каждой программе можно выделить своё-собственное адресное пространство, поскольку адрес 28 в одной программе означает иное физическое место, чем адрес 28 в другой программе?! ..далее мы рассмотрим простой способ, который использовался ранее, но вышел из употребления с появлением возможностей размещения на современных ЦП более сложных схем. Виртуальная память Проблемы программ, превышающих по объёму размер ОЗУ, возникли ещё на заре компьютерной эры. В 60-е годы было принято решение разбивать программы на небольшие части, называемые "оверлеями". При запуске программы в память, загружался только "администратор оверлейной загрузки", который тут-же запускал оверлей с порядковым номером 0. Когда "0" завершал свою работу, "администратор загрузки" грузил №1, и т.д. Некоторые оверлейные системы имели довольно сложное устройство, позволяя одновременно находиться в памяти множеству оверлеев. Оверлеи хранились на диске, и их свопинг с диска в память (и обратно) осуществлялся администратором загрузки оверлеев. Хотя работа по свопингу оверлеев с диска в память выполнялась операционной системой, разбиение программ на части выполнялось программистом в ручном режиме. Разбиение больших программ на небольшие/модульные части было очень трудоёмкой, скучной и не застрахованной от ошибок работой. Прошло не так-много времени, как был придуман способ, позволяющий возложить всю работу на компьютер. Изобретенный метод (Fotheringham, 1961) стал известен как "Виртуальная память". В основе виртуальной памяти лежит идея, что у каждой программы имеется собственное адресное пространство, которое разбивается на участки, называемые страницами:
Primary Memory **************************** Процесс System Размер 155 648 байт Базовый адрес 0х00010000 Значение Виртуальное Байт в странице 31х16=496 **************************** Процесс Explorer Размер 71 319 552 байт Базовый адрес 0х00010000 Значение Виртуальное Байт в странице 31х16=496Как видим из отчёта, оба процесса (System и Explorer) лежат в памяти по одинаковым-начальным адресам, т.е. имеют личное адресное пространство. Размер виртуальной страницы 496 байт (01F0h). Каждая страница представляет собой непрерывный диапазон адресов. Эти страницы отображаются на физическую память, но для запуска программы присутствие в памяти всех страниц - не обязательно. Когда программа ссылается на часть своего пространства, находящегося в физической памяти, аппаратное обеспечение осуществляет необходимое отображение на лету. Когда программа ссылается на часть пространства, которое НЕ находится в физической памяти, ОС предупреждается о том, что необходимо получить недостающую часть. При использовании виртуальной памяти, в блоках физической памяти может быть отображено всё виртуальное адресное пространство, ..а это 4 гига (для процессоров с шиной адреса 32бит).
Страничная организация памяти..с виртуальной памятью, понятие "адресного пространства приложения" приобрело другой смысл. Вместо того чтобы определять, как много памяти нужно приложению, операционная система с виртуальной памятью постоянно пытается найти ответ на вопрос: "Насколько мало памяти нужно приложению для работы?"Если в определённый момент времени в памяти находится только часть приложения, то где-же находится остальное? Ответить на этот вопрос можно просто: - остальная часть приложения находится на диске. Другими словами, диск служит своего рода дополнением оперативной памяти, и большое хранилище "поддерживает" более быструю память меньшего объёма. На первый взгляд может показаться, что это создаёт большие проблемы производительности, ведь диски работают намного медленнее памяти. Хотя это так, тем не менее, можно воспользоваться особенностями последовательного и локального доступа приложений, и решить большую часть проблем производительности, возникающих при использовании диска для расширения ОЗУ. Для этого подсистема виртуальной памяти организована так, что она пытается оставить в памяти только те части приложения, которые нужны в данный момент (или понадобятся в ближайшем будущем), и избавиться от них, как только они будут не нужны. В этом смысле, это похоже на принцип работы кэш-памяти: быстрое хранилище небольшого объёма и большое медленное хранилище вместе становятся большим и одновременно быстрым хранилищем. Прилагательное «виртуальное» означает, что это общее число адресуемых ячеек памяти, но не общий объём памяти, установленной в компьютере. Для реализации виртуальной памяти в компьютере должен быть специальный аппаратный механизм управления памятью. Этот механизм называют диспетчером управления памятью (Memory Management Unit, MMU). Если MMU отсутствует, при обращении процессора к памяти, реальный адрес в памяти никогда не меняется — адрес 123 всегда соответствует одной физической ячейке ОЗУ. Однако с MMU адреса проходят этап преобразования, прежде чем произойдёт обращение к памяти. Это значит, что адресу памяти 123 в одном случае может соответствовать физический адрес 82043, а в другом случае — физический адрес 20468. Но если сопоставлять виртуальные адреса физическим для каждого из миллиардов байт памяти, издержки будут слишком велики. Вместо этого, MMU делит ОЗУ на страницы — непрерывные блоки памяти заданного размера, которые рассматриваются MMU как одно целое. Может показаться, что введение страниц и преобразования адресов — дополнительный шаг, однако он очень важен для реализации виртуальной памяти. Давайте рассмотрим следующую ситуацию.. Предположим, что первая инструкция прикладной программы обращается к данным по адресу 10550. Также предположим, что в нашем компьютере всего 10000 байт физической памяти. Что произойдёт, если процессор попытается обратиться к адресу 10550? Произойдёт так называемая ошибка страницы. Ошибка страницы — это последовательность событий, происходящих, когда программа пытается обратиться к данным, которые отсутствуют в ОЗУ. ОС может обработать ошибки страницы, загрузив запрашиваемые данные в память, что позволит программе продолжить работу, как-будто никакой ошибки не было. В нашем случае процессор сначала передаёт нужный адрес (10550) устройству MMU. Однако, MMU не может преобразовать этот адрес. Поэтому MMU прерывает процессор и вызывает программу, так называемый "Обработчик ошибки страницы". Этот обработчик определяет, что нужно сделать для решения проблемы. Он может:
- найти, где находится на диске запрошенная страница, и прочитать её Тогда как первые три действия достаточно очевидны, последнее вовсе нет. Чтобы разобраться с ним, мы должны обсудить некоторые дополнительные темы. Набор страниц физической памяти, в данный момент выделенных определённому процессу, называется рабочим множеством этого процесса. Число страниц в рабочем множестве может (по-надобности) увеличиваться или уменьшаться. Рабочее множество процесса увеличивается при увеличении числа "ошибок страницы", и уменьшается по мере того, как остаётся всё меньше свободных страниц. Чтобы память не была израсходована полностью, время от времени страницы должны исключаться из рабочих множеств процессов и становиться свободными, доступными для дальнейшего использования. ОС сжимает "рабочие множества" процессов:
- записывая изменённые страницы в файл подкачки. Чтобы определить подходящий размер рабочих множеств всех процессов, операционная система должна следить за использованием всех страниц. Таким образом ОС определяет, какие страницы используются активно, а какие — нет, и следовательно, могут быть удалены из памяти. Для того, чтобы определить, какие страницы лучше удалить из рабочих множеств процессов, чаще всего применяется некая разновидность алгоритма учёта последних использованных страниц (стратегии кэширования). На компьютерах, не использующих виртуальную память, адреса выставляются непосредственно на шине памяти, что приводит к чтению/записи физической памяти с таким-же адресом. При использовании виртуальной памяти, виртуальные адреса не выставляются напрямую на шине памяти, а поступают в диспетчер памяти (MMU), который отображает виртуальные адреса, на адреса физической памяти:
+--------------------+ +-------+ +-------------+
| Запрос ЦП |-->>--| MMU |-->>-| Виртуальный |
| (физический адрес) | +-------+ | адрес |
+--------------------+ +-------------+
Страницы и страничные блоки имеют, как правило, одинаковые размеры. В реальных системах используются размеры страниц от 512 байт до 64 Кбайт, в зависимости от размера установленной ОЗУ.
Физические и виртуальные адресаНа рисунке б) изображена физическая память, состоящая из 4-х страничных блоков по 4 Кбайт (для процессора стиральной машины этого достаточно). Соответственно, первые 32 Кбайт виртуального адресного пространства (рис.а) разделены на 8 страниц по 4 Кбайт каждая.
Стр. | Виртуал. адрес
+------+---------------+
| 7 | 28672 - 32767 |
+------+---------------+
| 6 | 24576 - 28671 | Нижние 16 Кбайт адресов
+------+---------------+ основной памяти
| 5 | 20480 - 24575 |
+------+---------------+ Странич.
| 4 | 16384 - 20479 | блок Физ.адреса
+------+---------------+ +------+---------------+
| 3 | 12288 - 16383 | | 3 | 12288 - 16383 |
+------+---------------+ +------+---------------+
| 2 | 8192 - 12287 | | 2 | 8192 - 12287 |
+------+---------------+ +------+---------------+
| 1 | 4096 - 8191 | | 1 | 4096 - 8191 |
+------+---------------+ +------+---------------+
| 0 | 0 - 4095 | | 0 | 0 - 4095 |
+------+---------------+ +------+---------------+
а) б)
А теперь посмотрим, как 32-разрядный виртуальный адрес можно отобразить на физический адрес основной памяти. В конце концов, физическая память воспринимает только реальные, а не виртуальные адреса, поэтому такое отображение необходимо. Диспетчер памяти отображает 32-разрядный виртуальный адрес, на 15-разрядный физический, поэтому ему требуется 32-разрядный входной регистр и 15-разрядный выходной. Чтобы понять, как работает диспетчер памяти, рассмотрим пример на следующем рисунке:
|--- 15-разрядный физ.адрес --|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|1|1|0|0|0|0|0|0|0|0|1|0|1|1|0| Вых.регистр MMU
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Виртуальная
/ страница | | |
/ +--+--+-----------+-----------+
/ +-+------+ | |
7 |0| | ^ ^
+-+------+ | |
6 | | | | |
+-+------+ | |
5 |0| | | |
+-+------+ ^ ^
4 | | | ^ ^
+-+------+ | |
+->> 3 |1| 110 +---->>--->>----+ |
| +-+------+ |
| 2 | | | |
| +-+------+ |
| 1 |*+------+--- Бит присутствия |
| +-+------+ |
| 0 |*+------+--- Таблица страниц ^
| +-+------+ |
| |
+--------------+ |
| |
+------------------+--------------------+-----------+-----------+
| | |
|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|0|1|1|0|0|0|0|0|0|0|1|0|1|1|0| Вх.регистр MMU
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|
|-- 20-разрядная виртуальная страница --|-- 12разряд.смещение --|
| | |
| |
|----------------- 32-разрядный виртуальный адрес --------------|
Когда в диспетчер памяти поступает 32-разрядный виртуальный адрес, он разделяет этот адрес на 20-разрядный номер виртуальной страницы и 12-разрядное смещение внутри этой страницы. Номер виртуальной страницы используется в качестве индекса в таблице страниц (для нахождения нужной страницы). На рис. номер виртуальной страницы равен 3 (11b), поэтому в таблице выбирается элемент 3.Сначала диспетчер проверяет, находится-ли нужная страница в памяти. Поскольку виртуальных страниц всегда больше чем страничных блоков, не все виртуальные страницы могут находиться в памяти одновременно. Диспетчер памяти проверяет бит присутствия в данном элементе таблицы страниц. В нашем примере этот бит равен 1. Это значит, что страница в данный момент находится в памяти. Далее, из выбранного элемента таблицы нужно взять значение страничного кадра (в нашем примере 110) и скопировать его в старшие 3 бита 15-разрядного выходного регистра. Параллельно с этой операцией, младшие 12 бит виртуального адреса (поле смещения страницы) копируются в младшие 12 бит выходного регистра. Только теперь полученный 15-разрядный адрес отправляется в кэш-память или ОЗУ для поиска.
Менеджер памяти WindowsПамять представляет собой очень важный ресурс, требующий чёткого управления. Компьютеры обладают мегабайтами быстродействующей кэш-памяти, несколькими гигабайтами памяти (средней как по скорости, так и по цене), а также несколькими терабайтами памяти на довольно медленных/дисковых накопителях. Превратить эту иерархию в абстракцию, то есть в удобную модель, а затем управлять этой абстракцией — и есть задача операционной системы.Та часть ОС, которая управляет иерархией памяти называется менеджером памяти (MMU). Он предназначен для управления памятью и должен следить за тем, какие части памяти используются, выделять память процессам, которые в ней нуждаются, и освобождать память когда процессы завершат свою работу. Менеджер памяти ведёт несколько "списков состояния страниц" (см.рис), которые используют процессы и ОС. Всё крутится вокруг Рабочих Страниц (Working Set) - тех, которые используются операционной системой, драйверами, процессами и программами:
+-------------------------+
+----------------| |----------------+
| | РАБОЧИЕ | |
| +-------------| СТРАНИЦЫ |--------------+ |
| | | | | |
| | +----| |------------+ | |
| | | +-------------------------+ | | |
| | | | | |
| | +--->-------->-----------+ | | |
| | | | | |
| | +----------+ +-----------+ | +-----------+ | | |
| | | Модифиц. | | Обработка | +-->| Отстойник | | | |
| +->| страницы |--->| модифицир.|----->| |->+ | |
| +----------+ | страниц | +-----------+ | |
| +-----------+ | |
| | |
| +--------->>------------->>----------+ |
| | |
| +-----------+ | +-----------+ +------------+ |
| | Свободные |--+ | Обнуление | | Пустые | |
+->-->| страницы |--->| страниц |---->| страницы |-->--+
+-----------+ +-----------+ +------------+
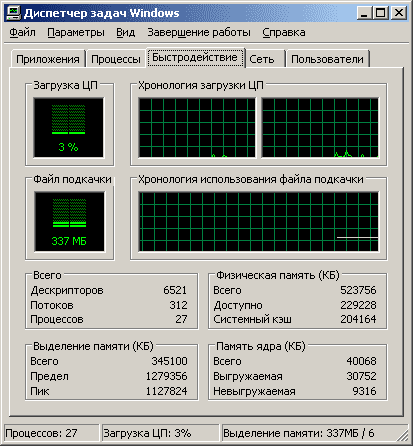
Если процесс пытается обратиться к странице, которой нет в списке "Рабочих страниц" процесса, то генерируется ошибка на уровне железа (Page Fault) и менеджер памяти может отвести ему новую страницу в виртуальной памяти.Если процесс освобождает страницу, то менеджер убирает её из списка "Рабочих страниц" и, если она была изменена, то помещает её в список Модифицированных Страниц (Modified Page List) для дальнейшей обработки, а после неё - в Отстойник (Standby List). В противном случае, cтраница сразу отправляется в "Отстойник". Менеджер памяти ведёт ещё 2 списка - Список Свободных Страниц (Free List) и список Пустых Страниц (Zeroed Page List). В список Свободных Страниц помещаются Страницы, которые освободились после окончания процесса. В список Пустых Страниц помещаются Страницы, которые заполнила нулями специальная подпрограмма Менеджера памяти (Zero Page Thread). Теперь посмотрим на данные, которые показывает "Диспетчер задач" [Ctrl+Alt+Del], на вкладке "Быстродействие":
* Доступно - это сумма объёмов "Отстойника", "Пустых" и "Свободных страниц"
Организация памяти в процессорах PentiumАдресное пространство WIN-32..после того как мы запустили какую-нибудь win32-программу, память может рассматриваться как один о-о-очень длинный ряд байтов. Байт может хранить одно из 256 различных значений (от 0 до 255). Что именно содержат эти байты, зависит от того, как интерпретировать их содержимое. К примеру, значение 97 может означать число 97, или-же "ANSI" букву 'a'. Если вы рассматриваете вместе несколько байт, то вы можете хранить и большие значения. Например, в 2-х байтах можно хранить одно из 256*256 = 65536 различных значений, две "ANSI" буквы 'ab' или "Unicode" букву 'a' - и т.д. Чтобы обратиться к конкретному байту в памяти (адресовать его), можно присвоить каждому байту номер, пронумеровав их целыми положительными числами, включив ноль за начало отсчёта. Индекс байта в этом огромном массиве и называется его адресом, а весь массив целиком - памятью программы. На уровне машинного языка (и ОС) все байты характеризуются:
* местоположением Местоположение - это адрес объекта. К примеру, число A может иметь адрес 1234, а число B - 1238. Это два разных числа, потому что у них разный адрес. Атрибут доступа определяет то, что можно делать с памятью: читать, писать и выполнять. ..последнее означает исполнение машинного кода. Тут нужно пояснить, что ваши данные (числа, строки и т.п.) находятся в одном "контейнере" вместе с кодом программы. Иными словами, код рассматривается наравне с данными, а чтобы их отличать - и служат атрибуты доступа. В современном мире программа работает исключительно с так-называемой "виртуальной памятью". Виртуальная память - это имитация реальной памяти. Она позволяет каждой программе:
* считать, что установлено максимальное количество ОЗУ; Иными словами, адресное пространство программы более не ограничено размером физической памяти. К примеру, если для адресации используются 32-битные указатели (4 байта), то размер адресного пространства равен:
11111111'11111111'11111111'11111111b = FFFF'FFFFh = 4'294'967'295d = 4 ГбВ связи с "новомодным переходом" на 64 бита нужно упомянуть, что этот переход заключается в замене 4-байтных указателей на 8-байтные, что увеличивает размер адресного пространства программы аж до:
1111111111111111'1111111111111111'1111111111111111'1111111111111111b = FFFFFFFF'FFFFFFFFh = 18'446'744'073'709'551'615d = 17'179'869'183 Гб = 16'777'215 Тб (терабайт)Соответственно, 32-битный указатель может быть любым числом от 0 до 4'294'967'296 (от $00000000 до $FFFFFFFF). 64-разрядный указатель может варьироваться от $00000000'00000000 до $FFFFFFFF'FFFFFFFF. Из этого следует, что у каждой Win32-программы есть 4 (win32) или 17179869183 (win64) Гб личной памяти!, т.е. каждой программе отводится своё личное/закрытое адресное пространство. Такая изолированность означает, что программа "А" в своем адресном пространстве может хранить какую-то запись по адресу $12345678, и одновременно у программы "В" по тому-же адресу, но уже в его адресном пространстве может находиться совершенно иная запись данных. Если программа "A" попробует прочитать данные по адресу $12345678, то она получит доступ только к своей записи, а не к данным программы "B". Иными словами, программа "A" не может обратиться к адресному пространству программы "B", и наоборот. Если программы выделяют в их адресных пространствах больше памяти, чем установлено ОЗУ, то часть памяти из ОЗУ переносится на диск/винчестер - в так-называемый файл подкачки (page file, SWAP). Когда программа обращается к своим данным, которые были выгружены на диск, то ОС автоматически грузит данные из файла подкачки в ОЗУ. И всё это происходит под капотом - т.е. совершенно незаметно для программы. С точки зрения программы, ей кажется, что она работает с 4 Гб паямти. Применение механизма виртуальной памяти позволяет:
* упростить адресацию памяти программами На машине с 512 Мб ОЗУ, любая программа может выделить, скажем, один кусок в 1 Гб памяти. Конечно-же, это не означает, что вы можете выделить аж 16 эксабайт, ведь реальный размер ограничен размером диска! Не факт, что в системе будет диск на 16 эксабайт. Тем не менее, это значительно лучше, чем просто 512 Мб ОЗУ, установленные на моей "старушке". Чем чаще системе приходится копировать данные из ОЗУ в "файл подкачки" и наоборот, тем больше нагрузка на жёсткий диск и тем медленнее работает ОС. При этом может получиться так, что ОС будет тратить всё-своё время на подкачку памяти, вместо выполнения программ. Поэтому, добавив компьютеру ОЗУ, вы снизите частоту обращения к жёсткому диску и, тем самым, увеличите общую производительность системы. Кстати, во многих случаях увеличение ОЗУ даёт бОльший выигрыш в производительности, чем замена старого ЦП на новый. Выравнивание адресов
Во всех РС память разделена на ячейки, которые имеют последовательные адреса. Байты группируются в 4-х или 8-байтные слова. Многие архитектуры компьютеров требуют, чтобы слова были выровнены в своих естественных границах. Так, 4-байтное слово может начинаться с адреса 0, 4, 8 и т.д., но не с адреса 1 или 2. Точно так-же, слово из 8 байт может начинаться с адреса 0, 8 или 16, но не с адреса 4 или 6. Механизм размещения 4-байтных слов в памяти иллюстрирует дамп ниже:
Выровненное/4-байтное слово в ячейки с адресом 20
Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F
00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000020 0E 1F BA 0E 00 00 00 00 00 00 00 00 00 00 00 00
Невыровненное/4-байтное слово в ячейки с адресом 4E
Offset 0 1 2 3 4 5 6 7 8 9 A B C D E F
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00000040 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0E 1F
00000050 BA 0E 00 00 00 00 00 00 00 00 00 00 00 00 00 00
Выравнивание адресов требуется довольно часто, поскольку при этом память работает наиболее эффективно. Если программа считывает 4-байтное слово с адреса 4E, диспетчер памяти должен сделать одно обращение к памяти, чтобы вызвать байты с 48 по 4F, а второе — чтобы вызвать байты с 50 по 57. Затем ЦП извлекает требуемые 4 байта из 16 (считанных из памяти), и компонует их в нужном порядке, чтобы сформировать 4-байтное слово.Карта виртуального адресного пространства В самом начале мы рассматривали память программы как один/непрерывный блок, сейчас настало время сделать уточнение, что я вам "наврал" - таковым оно не является! В нём есть несколько специальных областей. Не будем подробно разбирать их все, а замолвим пару слов только о самых важных. В виртуальном пространстве каждой программы, (со)существуют сама программа ..и операционная система. Та часть, где работает программа, называется "разделом для кода и данных пользовательского режима" (user mode). Часть, где работает операционная система, называется "разделом для кода и данных режима ядра" (kernel mode). Обе эти части находятся в едином адресном пространстве программы.
Чем они отличаются? Если мы говорим про 32-разрядную программу, то пользовательский раздел занимает пространство от 2 до 4Гб (по умолчанию 2). Соответственно, режим ядра занимает от 0 до 2Гб. Итого: по умолчанию адресное пространство 32-разрядной программы делится "по-братски" - половина нам, а половина операционной системе. Если говорить совсем точно, то раздел для данных юзера (в случае Win32) имеет диапазон:
$0000FFFF-$7FFEFFFF (с дыркой на 64 Кб в районе 2 Гб)
..а раздел режима ядра:
$80000000-$FFFFFFFF
В случае 64-разрядной программы ситуация несколько иная. В Windows соотношение выглядит так:
* user mode - $00000000'00010000-$000003FF'FFFEFFFF (8 Тб); * kernel mode - $00000400'00000000-$FFFFFFFF'FFFFFFFF.Здесь нужно сказать, что это только цифры, ведь на самом деле режим ядра (Win64) использует только несколько сотен Гб, оставляя бОльшую часть адресного пространства неиспользуемой. Т.е. у нас в дополнение к двум областям (user и kernel) появляется ещё и третья - зарезервированная область. Сделано это по-той/простой причине, что 64-битное адресное пространство настолько ОГРОМНО, что "user" и "kernel mode" выглядели бы в нём тонюсенькими полосочками, вздумай-бы мы изобразить их графически. Если место просто зарезервировано, то и не нужно делать для него управляющих данных. Даже 8 Тб памяти для "user mode" - это очень много. Если-бы мы выделяли мегабайт памяти в секунду, у нас-бы ушло три месяца, чтобы исчерпать такое адресное пространство! Из всего/вышесказанного следует, что размер памяти программы (exe, dll) ограничен 2 Гб (32-битная программа) или 8 Тб (64-битная программа), либо суммарным размером ОЗУ и файлом подкачки. На практике вы получаете "out of memory" только когда превышаете размер в 2 Гб.
|